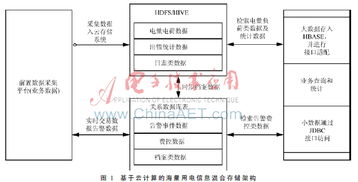
基于Hadoop与关系型数据库的电力用采大数据混合服务架构
随着智能电网的快速发展,电力用采系统每天产生海量的实时数据,传统的关系型数据库在存储和处理这些大数据时面临性能瓶颈。为了应对这一挑战,结合Hadoop分布式计算框架与关系型数据库的混合服务架构应运而生,成为电力用采大数据处理的高效解决方案。
一、混合架构的设计理念
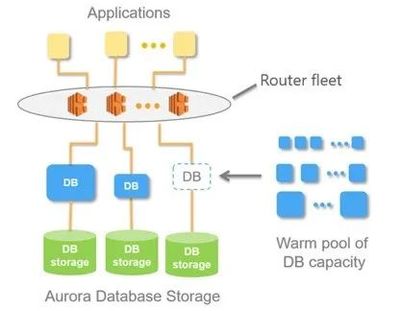
电力用采大数据混合服务架构的核心在于充分发挥Hadoop和关系型数据库各自的优势。Hadoop生态系统(如HDFS、MapReduce、Spark)擅长处理非结构化和半结构化数据,支持高吞吐量的批处理操作;而关系型数据库(如MySQL、PostgreSQL)则适用于事务性操作、复杂查询和数据一致性要求高的场景。通过将两者结合,可以实现数据的分层存储与处理:原始数据和历史数据存储在Hadoop中,而频繁访问的汇总数据、元数据和业务规则则保留在关系型数据库中。
二、架构组成与数据流向
该混合架构通常包括以下组件:
- 数据采集层:通过物联网设备、智能电表等收集电力用采数据,并传输至数据接入网关。
- 数据存储层:原始数据首先进入Hadoop分布式文件系统(HDFS),用于长期存储和批量分析;同时,关键业务数据(如用户信息、计费规则)存储在关系型数据库中。
- 数据处理层:利用MapReduce或Spark对Hadoop中的数据进行ETL(提取、转换、加载)、数据清洗和聚合分析,结果可导入关系型数据库供业务系统使用。
- 服务接口层:提供统一的RESTful API或数据服务,支持前端应用、报表系统和实时监控平台从混合数据源中获取信息。
三、优势与应用场景
混合架构在电力用采大数据服务中具有显著优势:
- 高可扩展性:Hadoop支持横向扩展,轻松应对数据量增长。
- 成本效益:利用Hadoop存储低成本的历史数据,降低硬件投资。
- 实时与批量处理结合:关系型数据库处理实时查询,Hadoop处理离线分析,满足多样业务需求。
- 数据完整性:通过关系型数据库保障事务一致性,避免数据冲突。
典型应用包括用电负荷预测、故障检测、用户行为分析和智能计费。
四、挑战与优化策略
尽管混合架构优势明显,但也面临数据同步、系统复杂性和运维难度等挑战。为此,可采取以下优化措施:
- 使用数据同步工具(如Sqoop、Kafka)实现Hadoop与关系型数据库之间的高效数据流转。
- 引入数据仓库技术(如Hive)简化Hadoop查询,提升开发效率。
- 实施监控与告警机制,确保系统稳定运行。
基于Hadoop和关系型数据库的电力用采大数据混合服务架构,通过互补技术融合,不仅提升了数据处理能力,还推动了电力行业的智能化转型。未来,随着边缘计算和人工智能技术的融入,这一架构将进一步完善,为电力系统提供更强大的数据支撑。
如若转载,请注明出处:http://www.1dingyouchebeta.com/product/32.html
更新时间:2025-11-29 03:41:19